Minor Pipelines
in Multiple Pipelines
in Multiple Pipelines
This page is still under construction!
A minor pipeline is a pipeline that was created by its major pipeline. The minor pipeline runs on the most suitable computer in a gridcluster or supercomputer according to its settings that was generated by its major pipeline. The minor pipeline runs on a job script, in which other scripts and programs are called. This job script is also the minor highway bash script.
Because the major pipeline generates more minor pipelines, more job script have been generated. Each job script is supposed to work on only 1 computer. On that computer, the data set is being analyzed and processed and the final results are generated.
All these minor pipelines work in parallel in the gridcluster or supercomputer and they do not work in series. As you can imagine, this shortens the time of processing all data very much. If 3 data sets of the same sizes are processed in parallel, everything is 3 times faster than if those 3 data sets would be processed in series.
Structure of a minor pipeline:
Each minor pipeline in a multiple pipeline is different, but they all have the same stucture. This structure is from top to bottom as follows:
Header with settings for the computer, on which that minor pipeline will operate.
The header contains the following settings:
Header with settings for the computer, on which that minor pipeline will operate.
The header contains the following settings:
- Name of the minor pipeline in the job script
- Number of nodes
- Number of cores per node
- Calculation time
- Amount of memory needed
- Output file name, in which the results of the minor pipeline will be saved.
- Output file name, in which the errors will be saved.
- Minor highway bash script, in which other scripts and programs are called.
MORE TO COME...
To make submissions of these minor pipelines with its data sets possible, the major pipeline generates a submit job script. In this submit job script, all the jobs - with its minor pipelines and its data sets - have been put in a queue. This submit job script will be submitted at the end. Then, the minor pipelines start running.
To make submissions of these minor pipelines with its data sets possible, the major pipeline generates a submit job script. In this submit job script, all the jobs - with its minor pipelines and its data sets - have been put in a queue. This submit job script will be submitted at the end. Then, the minor pipelines start running.
According to the settings, the minor pipeline will analyze its data on the right computer.
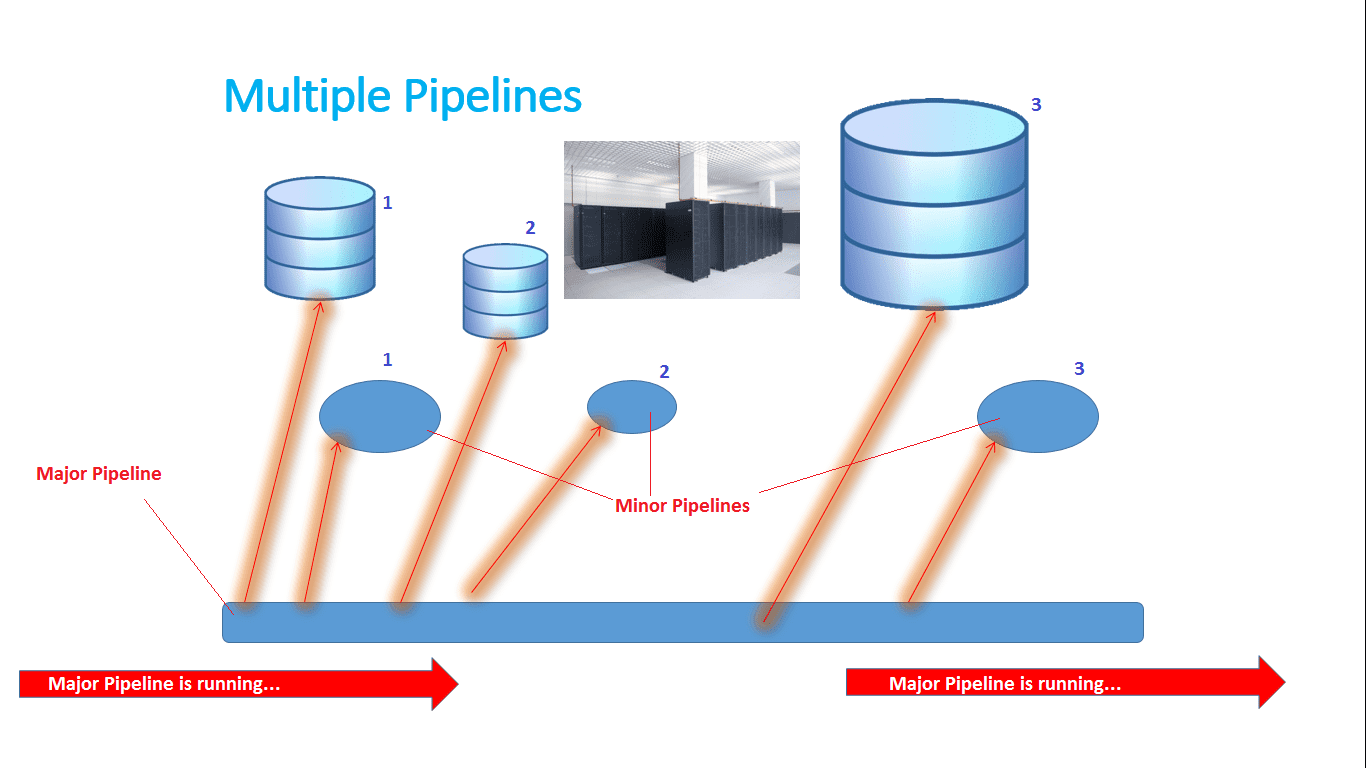
Figure ...: Overview of how a multiple pipeline works.
In this figure, you can see how a multiple pipeline works in combination with its minor pipelines. When the major pipeline is running, it is creating minor pipelines in jobs. According to the conditions of each data set, a special minor pipeline is created that is totally suited for analyzing its specific data set. Each minor pipeline is put into a job. Each job can be submitted,
In this figure, you can see how a multiple pipeline works in combination with its minor pipelines. When the major pipeline is running, it is creating minor pipelines in jobs. According to the conditions of each data set, a special minor pipeline is created that is totally suited for analyzing its specific data set. Each minor pipeline is put into a job. Each job can be submitted,
Figure ... shows how a multiple works. According to this figure, there will be explained what is happening.
The main task of the major pipeline is generating minor pipelines according to the data sets that have to be processed. In figure ..., you can see that there are 3 data sets. Data set number 1 represents a medium size data set. Data set number 2 represents a small data set. Data set number 3 represents a large data set.
When the major pipeline is started, scanning of the first data set begins. The major pipeline first scans data set number 1. The major pipeline determines what type of data it is, what size it has, calculates how much memory it needs for the analyses, calculates how long the calculation time will be, etc. Briefly, the major pipeline first determines the conditions (settings) for processing the data in that data set. These settings will be put in the header section of the job script of the minor pipeline. When the job is submitted, the job script and the minor pipeline in it will run on the very most suitable computer for processing and analyzing these data. This is also done with the data sets numbers 2 and 3. For these data sets, separate minor pipelines are generated with their own settings.
When the major pipeline has generated all the job scripts and minor pipelines, it will create a so-called submit job script. In this submit job script, each minor pipeline has been written as a job script and put into a queue. After that, the major pipeline has finished its job.
All the minor pipelines can be started now with this submit job script. This can be started by typing:
bash SubmitJobs.sh
bash SubmitJobs.sh
All the jobs are submitted then and put into the queue. When a computer is free again, the job with most suitable settings will be taken for processing its data set on that with its minor pipeline.
When all the minor pipelines did their jobs, all the data sets have been analyzed and processed. Mostly, all the results of the separate minor pipelines will be joined together. Therefore, a single pipeline could programmed for it.
